Recognizing DB failover and steps to take when it occurs
If Server Cluster determines that the Master database has become unreachable for a certain (configurable) amount of time, it begins a failover process that creates special logging and directs the Standby database to promote itself to Master. Internal database connections will be passed on to the new master/old standby. Clarify Server Cluster should continue operating with little to no interruption.
Whenever database failover occurs in the middle of processing, Clarify attempts to correctly update the logs and successfully complete processing. Still, there may be times when processing fails to complete during the failover process.
The special logging provides important information that can be used to recognize the failover and identify/reconcile errors, should they appear.
Trigger files
When Clarify determines that it is time to initiate failover, it writes two files to a trigger folder in the Shared directory of the Server Cluster install: failover.trigger and failoverLog.token. The first is read by the Standby database, triggering the promotion to Master. The second initiates the creation of separate failover logs.
The fact that these files appear in the trigger folder indicates that failover has occurred. By configuring Clarify to send notifications whenever the failoverLog.token appears is a simple but effective way to be alerted when a database fails over.
Failover logs
The failover process creates special log files with additional information, filtering out errors with the error codes specified in the ebi.database.errorCodes property in the shared.properties file. Both logs are found in <Clarify Install Directory/Clarify_4_Share>:
- /logs/database_failover_${timestamp}
- /nodes/workerNode_${count}/database_failover_${timestamp}
The first log notes that failover has been initiated. Here is an example:
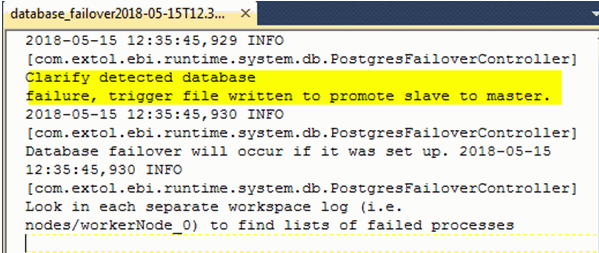
The second log lists processes running during the failover, the time that the failure was first detected, and the time that connection to the new master was established, and any exceptions related to the above mentioned error codes.
Identifying and reconciling errors
Using information in the failover logs, and comparing it to logs in the Auditor, you should be able to determine which processes completed successfully and those that did not. In that case, the records in question could either be Reprocessed from the Auditor or resent (e.g. dropping a file in the File Monitor, resending from Harmony, etc). Clarify attempts to set any processes that were in ‘mid-flight’ during failover to a failed status.
- Logs with a status of Received Only may need to be processed from scratch (not using the reprocessing button).
- Logs with a status of Failed can be reprocessed.
Troubleshooting tips
- Use email notifications in Clarify to alert when files are written to the trigger folder.
- Review Connection logs by using the Status Checks log filter group in the Auditor and selecting Unsuccessful Connections
- Recognize the time-window that the database failover occurred; knowing which processes may have ran during this time will help isolate the possible errors.